المشكلة الكبيرة , يمكن حلها بالتجزئة … ال MapReduce
تحدثنا في الموضوع السابق عن البيانات الضخمة وأهميتها اليوم في تحديد الكثير من القرارات , ولكن عندما نفكر في الموارد والطاقه فهي محدودة مها كانت.
ومن أشهر الطرق التي عهدناها كمطورين في تخزين البيانات هي قواعد البيانات , نظرا لسهولة إستخراج وإدخال البيانات بلغة ال SQL حيث تقوم بتخزين البيانات على القرص الصلب الخاص بالأجهزة.
ومع زيادة الحاجة لزيادة حجم البيانات والتأكد من سلامتها وعدم خسارة جزءا منها , كان لابد من وجود نسخ مكررة فعالة ومتزامنة بحيث عند وجود أي مشاكل في أي بيانات يمكن إستبدالها , وكذلك توزيع الحمل على أكثر من جهاز وليس جهاز واحد
وهنا بدأت شركات قواعد البيانات في مطلع التسعينات أمثال Oracle و Mysql و MS Sql Server وغيرها بتبني فكرة أن تكون قواعد البيانات تعمل بنظام موزع ومتوازي بما يعرف ب Parallel DBMS حيث ما زالت جهات كثيره تستخدم هذه الطريقة لتخزين المعلومات
جنون المعلومات لم يستطيع الإعتماد على ال Parallel DBMS لأن حجم البيانات للشركات الضخمة أصبح مهولا , وأصبحت مشكلة كبيرة جدا تزامن الشركات لأنها تحتاج إلى معالجة سريعة ودورية مع بقاء الأنظمة فعالة , من كان لا بد من الإعتماد على طريقة يمكن توزيعها على عدد كبير من الأجهزة وتكرارها ونقلها بسهولة
ال MapReduce
قامت شركة جوجل بنشر هذا المبدأ ليكون نواة للكثير من البرمجيات فيما بعد لحل المشاكل الضخمة ومنها البيانات والمعالجات , والمبدأ يقوم على تقسيم المشكلة الكبيرة إلى عدة أجزاء بحيث يمكن لكل جزء معالجته على حده من أجهزة رخيصة الثمن وبعد ذلك يتم تجميع هذه الحلول في حل واحد ليكون حل المشكلة الكبيرة وبهذه الطريقة أصبحت التكلفة أقل
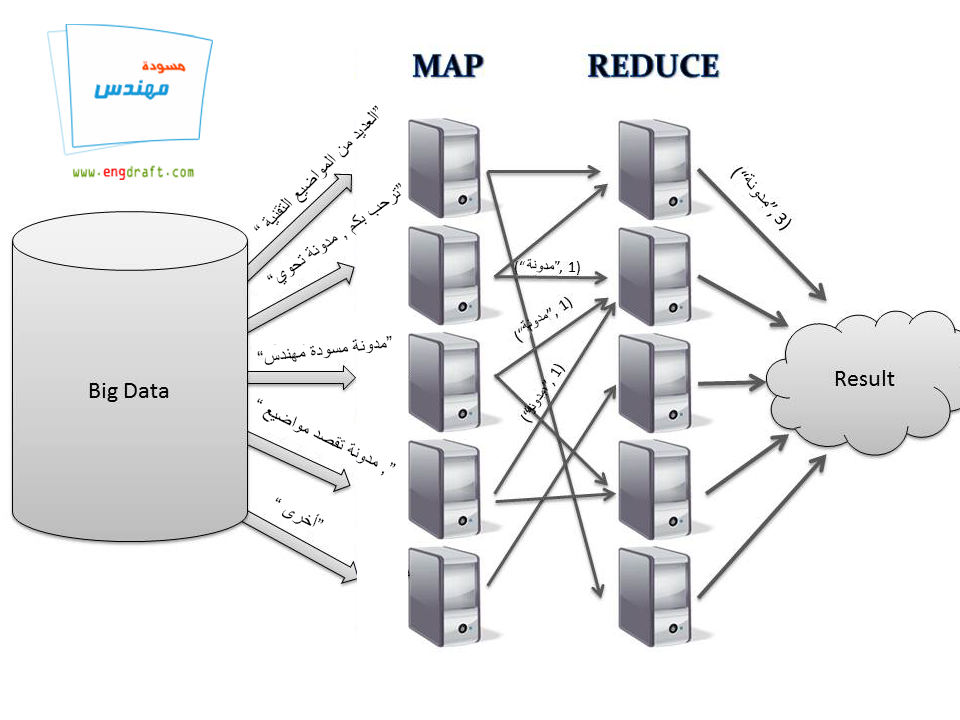
بمثال بسيط نفرض أنه لدينا نص ” مدونة مسودة مهندس ترحب بكم , مدونة تحوي العديد من المواضيع التقنية , مدونة تقصد مواضيع أخرى”
وبفرض أننا نبحث عن كلمة “مدونة” ولنفرض أنه لدينا 4 أجهزة سنقوم بتقسيم النص إلى 4 وتوزيعها إلى كل جهاز بحيث يقوم كل جهاز بالبحث عن كلمة “مدونة” وفي حال وجدها يقوم بتعليمها (Map) ومن ثم إرسالها إلى جهاز التجميع (Reduce) حيث يحسب جهاز التجميع القيم ويرسلها كناتج , وبالتالي بعد تحصيل كل التجميعات تكون النتيجة.
{kind=link}
وبالطبع يكون الأمر أكثر تعقيدا حيث يمكن لتجميع (Reduce) التسليم لجهة (Map) اخرى.
قد يتساءل البعض هل لماذا لم تقضي هذه الطريقة على ال Parallel DBMS , الحقيقة أن الأمر متعلق بحجم المشكلة , فالمشكلة عندما تحتاج إلى أكثر من 1000 جهاز لحلها فإن الأمر يكون فعالا لإستخدام ال Map Reduce أما عدا ذلك فالأفضل هو إستخدام ال DBMS , كما أنه هناك تقنيات غير موجودة في ال Map Reduce مثل ال indexing , سهولة كتابة الإستعلامات وفهمها.
ولكن في المشاكل الكبيرة التي تتعرض إليها الشركات الكبيرة يوميا تحتاج إلى الفعالية الدائمة , لذلك تقوم هذه الشركات بتخصيص مزرعة من الخوادم لتوزع عليها المهام بشكل يومي , هذه المزرعة مليئة بال Clusters حيث يحوي كل Cluster مجموعة من الأجهزة يتم توزيع المهام عليها يوميا
{kind=link}
تطبيقات على ال Map Reduce
ال MapReduce هو مبدأ ولكن تم التطوير عليه ليعمل على أرض الواقع في بعض التطبيقات , ومنها ال Hadoop المطور بواسطة Yahoo والذي إنضمت إليه الشركات لدعمه لاحقا ليكون من أكبر المشاريع المفتوحه الخاصة بمعالجة البيانات الضخمة.
كما أن ال PIG والذي طور بواسطة Yahoo يعمل بكتابة أكواد بسيطة تساعد في عمل تطبيقات تعالج البيانات الضخمة.
وهناك مشاريع تم تطويرها على ال Hadoop نفسه مثل ال Hive والذي تم تطويره بواسطة Facebook لتسهيل كتابة SQL ومن ثم تحويلها إلى Jobs يسهل توزيعها على الأجهزة.
{kind=link}
{kind=link}
كان هذا مقدمة عن ال MapReduce لمعالجة المشاكل الضخمة , سنتحدث لاحقا عن المزيد من التقنيات في مجال ال BigData
دمتم بود
إلى تدوينة أخرى
مصادر
[Dean et al., CACM 2008] MapReduce: Simplified Data Processing on Large Clusters, J. Dean, S. Ghemawat, In CACM Jan 2008
[Dean et al., CACM 2010] MapReduce: a flexible data processing tool, J. Dean, S. Ghemawat, In CACM Jan 2010
[Stonebraker et al., CACM 2010] MapReduce and parallel DBMSs: friends or foes?, M. Stonebraker, D. J. Abadi, D. J. DeWitt, S. Madden, E. Paulson, A. Pavlo, A, Rasin, In CACM Jan 2010
[Pavlo et al., SIGMOD 2009] A comparison of approaches to large-scale data analysis, A. Pavlo et al., In SIGMOD 2009
[Abouzeid et al., VLDB 2009] HadoopDB: An Architectural Hybrid of MapReduce and DBMS Technologies for Analytical Workloads, A. Abouzeid et al., In VLDB 2009