

لنبدأ بهذا الرقم 2500,000,000,000,000 هو عدد ال bytes التي قام البشر بإدخالها في كل يوم في عام 2012 ولم يسبق للبشرية من قبل أن خزنت كل هذا الكم من المعلومات [1]
90% من البيانات المتوفرة في العالم تم إنشاءها في اخر سنتين , نظرا لما وفره الإنترنت من سهولة لإدخال المعلومات ومشاركتها وتخزينها [2]
و يتوقع في العام 2015 أن يكون هناك 3 بليون شخص على الإنترنت يقومون بنشر معلومات بحجم 8 زيتا بايت يوميا [3]
وعندما نتحدث بلغة الأرقام فهناك أرقام وأرقام كثيرة م
ثيرة للدهشة في هذا المجال , فربما تجد مقالة تتحدث عن حجم البيانات الكبير جدا في الشبكات الاجتماعية أو الهواتف الذكية أو الحركات المالية وغيرها
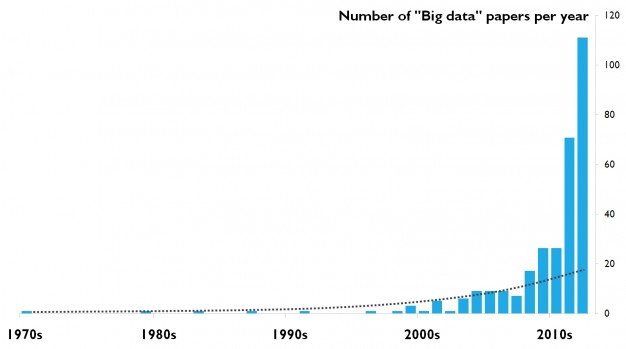
لذلك بدأ يظهر مفهوم البيانات الضخمة (BIG Data) في السنوات الاخيرة كتحدي للشركات و كعنوان للبحث العلمي فعدد الأوراق المنشورة في العامين السابقين يعادل ما تم نشره في تاريخ البحث
ماهي البيانات الضخمة (BIG Data)
بحسب تعريف الويكبيديا هي مجموعة من البيانات الكبيرة جدا والمعقدة والتي يصعب معالجتها وإدارتها بإستخدام الطرق والتطبيقات المتعارف عليها [4]
ويعد ال Big Data مفهوم نسبي بمعنى أنه يقاس بحجم كل مؤسسة فبعض المؤسسات قد ترى أن البيانات التي تتعامل معها ضخمة جدا بينما تكون لا تساوي شيئا بالنسبة لمؤسسة اخرى !
ماقيمة هذه البيانات , هل نحن بحاجة إلى تخزين هذه البيانات؟
نعم يتساءل البعض لماذا علينا أن نخزن كل هذا الكم من المعلومات , فالأمر مكلف , ولماذا لا تكون المعلومات لحظية ؟
بداية لنتفق بأننا نعيش في زمان من يملك المعلومة فيه هو من يملك القوة , لذلك لا تضيع أي من الشركات الكبرى أمثال جوجل وفيسبوك وغيرها أي فرصة لحفظ أي معلومة فمثلا جوجل لا تضيع فرصة حفظ جميع نتائج بحث المستخدمين وحتى وإن قمت بكتابة أي شيء في حقل البحث دون البحث , وحتى مدة إنتظارك وتأملك في نتائج البحث , وحركات الفأرة التي تقوم بها , كما أن فيسبوك يقوم بتخزين كل المعلومات حتى التي قمت بحذفها , وغيرها
بالتأكيد هذه المعلومات لها قيمة كبيرة فمجرد إمتلاكها يعد ثروة , ومن يستطيع إدارتها ومعالجتها والإستفادة من نتائجها فإنه سيحقق الكثير من النجاحات
فعلى الصعيد التجاري بظهور علم العمل الذكي (Business Intelligent) والذي يستطيع إتخاذ القرارات بشكل أتوماتيكي من خلال البيانات السابقه والتعلم , بحيث يقوم بإظهار النتائج لأصحاب العمل في أي الأوقات التي تناسب الزبائن وماهي البضائع التي يفضلونها وما هو أفضل وقت لتوريد البضائع وماهو أفضل وقت لبيع المنتجات , وما العلاقة بين المنتجات …وإلخ من العلاقات التي يصعب تكوينها
كما أن في مقدوره إتخاذ القرار مباشرة (طلب توريد , بيع …إلخ)
كما أنه يمكن إستعمالها في القطاع الصحي بمعرفة وتوقع الأمراض من خلال مجموعة الأعراض التي تعرض لها مجموعة كبيرة من المرضى وربط الخصائص وإكتشاف علاقتها بالأمراض والعقارات
وقس على ذلك القطاعات المختلفة إلى أن تصل إلى القرارات الحكومية التي بدأت تعمل بجد في هذا المجال لتربط قرارتها بناء على خبرة البيانات السابقة !
نموذج ال (3V (Volume , Velocity , Variety :
ويمكن من خلاله قياس أبعاد البيانات الضخمة بتعيين مدى درجة حجمها وتعقيدها والأداء الخاص بمعالجتها

نتحدث لاحقا عن التقنيات المستخدمة في البيانات الضخمة
دمتم بود إلى تدوينة اخرى
المصادر
[1] – [2] radicati.com , news.cnet.com , blog.kissmetrics.com ,businessinsider.com , americanis.net
[3] Asigra
[4] wikipedia
[5] techtarget


")
